In this blog, we will be discussing various techniques to vectorize the texts in NLP.
Before we move forward let us briefly discuss what is NLP.
NLP (Natural language processing) is a branch of artificial intelligence that helps machines to understand, interpret and manipulate human language.
Since the beginning of the brief history of Natural Language Processing (NLP), there has been the need to transform the text into something a machine can understand.
We all know that computers don’t understand English or any language as it is. They only understand binary language that is only 1 and 0 (Bits). Thus, arises the need to transform the text into a meaningful vector (or array) of numbers (or simply to encode the text), so that the computer can better understand the text and hence the language.
Machine learning algorithms most often take numeric feature vectors as input. Thus, when working with text documents, we need a way to convert each document into a numeric vector. This process is known as text vectorization. In much simpler words, the process of converting words into numbers is called Vectorization.
Before actually diving into the whole process of vectorization. Let us first set a corpus to work with, we will be choosing a very common example, you might have seen it on various websites.
corpus = [
'the quick brown fox jumped over the brown dog.',
'the quick brown fox.',
'the brown brown dog.',
'the fox ate the dog.'
]Our corpus consists of four sentences, these four sentences can be thought of as four different documents. Now that we have our corpus we will get on with vectorization. Vectorization is better understood with examples.
The following are the different ways of text vectorization:
CountVectorizer
It is a great tool provided by the sci-kit-learn library in Python. It is used to transform a given text into a vector on the basis of the frequency (count) of each word that occurs in the entire text.
Documentation: https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html
CountVectorizer creates a matrix in which each unique word is represented by a column of the matrix, and each text sample from the document is a row in the matrix. The value of each cell is nothing but the count of the word in that particular text sample as shown below.
For the corpus above, our matrix would be something like as follows.

The first sentence or the document would be transformed into a vector [02111112]. In a similar manner, each document can be represented by a vector.
Let us try to code it and see the result for ourselves.
The CountVectorizer provides a simple way to both tokenize a collection of text documents and build a vocabulary of known words, but also to encode new documents using that vocabulary.
You can use it as follows:
1. Create an instance of the CountVectorizer class.
2. Call the fit() function in order to learn a vocabulary from one or more documents.
3. Call the transform() function on one or more documents as needed to encode each as a vector.
An encoded vector is returned with a length of the entire vocabulary and an integer count for the number of times each word appeared in the document.
Code snippet:
from sklearn.feature_extraction.text import CountVectorizer
# create an object of CountVectorizer class.
vectorizer = CountVectorizer()
# tokenize and build vocabulary
vectorizer.fit(corpus)
# encode
vector = vectorizer.transform(corpus)
# summarize encoded vector
print('Vocabulary :',vectorizer.vocabulary_)
print('\nShape of the vector: ',vector.shape)
print('\ntype of vector: ',type(vector))
print('\nBelow are the sentences in vector form:')
print(vector.toarray())Output:

We can see that we got the same result as above. Now you must be getting what it means to vectorize text. Once the text is vectorized it is ready to be fed to machine learning models as an input.
Let us try out some more methods to perform vectorization.
TfIdfVectorizer
It is another one of the great tools provided by the scikit-learn library.
It is a very common algorithm to transform the text into a meaningful representation of numbers which is used to fit machine algorithms for prediction.
TF-IDF is a product of two terms:
TF (Term Frequency) — It is defined as the number of times a word appears in the given sentence.
IDF (Inverse Document Frequency) — It is defined as the natural log of a number of the total documents divided by the documents in which the word appears.
For example, we will calculate the Tf-Idf values for the first sentence in the corpus.
Step 1: Create a vocabulary of unique words. In our case the vocabulary would be:
['ate', 'brown', 'dog', 'fox', 'jumped', 'over',' quick', 'the'].
Step2: Create an array of zeroes for each sentence in the corpus, with a size equal to the number of unique words in the corpus. For e.g. the array for the first sentence would be [00000000]. In this way, we will get 4 arrays of length 8.
Step3: We calculate Tf-Idf for each word in each sentence. We select the first sentence to illustrate this step.
We know that:
Total documents/sentences (N): 4 Documents in which the word appears (n): 3 Number of times the word appears in the first sentence: 1 Number of words in the first sentence: 9 Term Frequency (TF) = 1 **If smooth_idf=True (the default), the constant “1” is added to the numerator and denominator of the idf as if an extra document was seen containing every term in the collection exactly once, which prevents zero divisions: idf(t) = log [ (1 + n) / (1 + df(t)) ] + 1.** Inverse Document Frequency(IDF) = ln((1+N)/(1+n))+1 = ln(5/4)+1 = 0.22314355131 + 1 = 1.22314355131 TF-IDF value = 1 * 1.22314355131 = 1.22314355131 Same way Tf-Idf is calculated for each word in the vocabulary and then the values obtained are normalized. In TfIdfVectorizer the parameter 'norm' has a default value of 'l2'. In this case, the sum of squares of vector elements is 1. If the norm is set as 'l1', then sum of absolute values of vector elements is 1. We can also set value of norm parameter to be 'False' and not opt for any kind of normalization at all. The Tf-Idf values for all the words in the first sentence is: 'ate': 1.916290731874155, 'brown': 2.44628710263, 'dog': 1.2231435513142097, 'fox': 1.2231435513142097, 'jumped': 1.916290731874155, 'over': 1.916290731874155, 'quick': 1.5108256237659907, 'the': 2.0 After applying the default norm in TfIdfVectorizer i.e. the 'l2' norm. We get the following values: 'ate': 0.0, 'brown': 0.51454148, 'dog': 0.25727074, 'fox': 0.25727074, 'jumped': 0.40306433, 'over': 0.40306433, 'quick': 0.31778055, 'the': 0.42067138
Thus the vector for the first sentence would be: [0. 0.51454148 0.25727074 0.25727074 0.40306433 0.40306433 0.31778055 0.42067138]
Let us try to code it and see the result for ourselves.
The implementation is similar to CountVectorizer, but in this case we make an object of the TfIdfVectorizer class instead of the CountVectorizer.
Code snippet:
from sklearn.feature_extraction.text import TfidfVectorizer
# create an object of TfidfVectorizer class.
vectorizer = TfidfVectorizer()
# tokenize and build vocabulary
vectorizer.fit(corpus)
# encode
vector = vectorizer.transform(corpus)
# summarize encoded vector
print(vectorizer.vocabulary_)
print(vectorizer.idf_)
print(vector.shape)
print(vector.toarray())Output:

The TfIdfVectorizer will tokenize documents, learn the vocabulary and inverse document frequency weightings, and allow you to encode new documents. Alternately, if you already have a learned CountVectorizer, you can use it with a TfidfTransformer to just calculate the inverse document frequencies and start encoding documents.
HashingVectorizer
This is also a method provided by scikit-learn. It also converts a collection of text documents to a matrix of token occurrences just like CountVectorizer but the process is a little different.
Documentation: https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.HashingVectorizer.html
The vocabulary build while working with CountVectorizer can become very huge when the size of the documents increase. This, in turn, will require large vectors for encoding documents and impose large requirements on memory and slow down algorithms and also it would take up a lot of memory. In order to get around this HashingVectorizer is used.
In HashingVectorizer we use a one way hash of words to convert them to integers. The best part is that, in this case no vocabulary is required and you can choose an arbitrary-long fixed length of the vector.
A downside is that the hash is a one-way function so there is no way to convert the encoding back to a word (which may not matter for many supervised learning tasks).
Here the vectorizer does not require a call to fit on the training data documents. Instead, after creating the object, it can be used directly to start encoding documents.
We can set the length of vector by assigning the value to the parameter 'n_features'. In this example we will create a vector of length 10. It is acceptable since our documents are very small. In case of large documents the value of n_features should be such that it can avoid hash-collisions.
code snippet:
from sklearn.feature_extraction.text import HashingVectorizer
# create an object of HashinVectorizer class.
vectorizer = HashingVectorizer(n_features=10)
# encode directly without fitting
vector = vectorizer.transform(corpus)
# summarize encoded vector
print('\nShape of vector: ',vector.shape)
print('\nBelow are the sentences in vector form:')
print(vector.toarray())Output:

The values of the encoded document correspond to normalized word counts by default in the range of -1 to 1, but could be made simple integer counts by changing the default configuration.
The above three methods were Bag of words approach provided by scikit learn. The next approaches would be that of neural network model.
Word2Vec
Word2vec is a combination of models used to represent distributed representations of words in a corpus. It is a set of neural network models that aim to represent words in the vector space. These models are highly efficient and well performing in understanding the context and relation between words. Similar words are placed close together in the vector space while dissimilar words are placed wide apart.
Documentation: https://radimrehurek.com/gensim/models/word2vec.html
There are two models in this class:
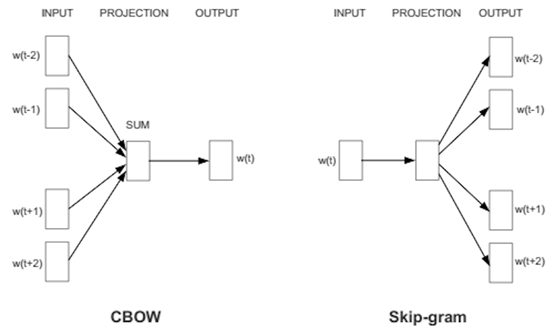
CBOW (Continuous Bag of Words): The neural network takes a look at the surrounding words (say 3 to the left and 3 to the right or whatever may be the window size) and predicts the word that comes in between.
code snippet:
from gensim.models import word2vec
for i, sentence in enumerate(corpus):
tokenized= []
for word in sentence.split(' '):
word=word.split('.')[0]
word = word.lower()
tokenized.append(word)
corpus[i] = tokenized
model1 = word2vec.Word2Vec(corpus, workers = 1, size = 2, min_count = 1, window = 3, sg = 0)
vocabulary1 = model1.wv.vocab
print(vocabulary1)
v1 = model1.wv['fox']
print('\nShape of vector: ',v1.shape)
print('\nBelow is the vector representation of the word \'fox\':')
print(v1)Output:

2. Skip-grams: The neural network takes in a word and then tries to predict the surrounding words (context). The idea of skip gram model is to choose a target word and then predict the words in it’s context to some window size. It does this by maximizing the probability distribution i.e. probability of the word appearing in the context (within the specified window) given the target word.
code snippet:
model2 = word2vec.Word2Vec(corpus, workers = 1, size = 3 ,min_count = 1, window = 3, sg = 1)
vocabulary2 = model2.wv.vocab
print(vocabulary2)
v2 = model2.wv['fox']
print('\nShape of vector: ',v2.shape)
print('\nBelow is the vector representation of the word \'fox\':')
print(v2)Output:

Notice in this case I have set the size of the vector to be 3 thus the vector in this case have three elements in it.
ElMo
ElMo stands for Embeddings from Language Models. ElMo is a deep contextualized word representation that models both
(1) complex characteristics of word use (e.g., syntax and semantics), and
(2) how these uses vary across linguistic contexts (i.e., to model polysemy).
These word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pre-trained on a large text corpus. They can be easily added to existing models and significantly improve the state of the art across a broad range of challenging NLP problems, including question answering, textual entailment and sentiment analysis.
Unlike traditional word embeddings such as word2vec, the ElMo vector assigned to a token or word is actually a function of the entire sentence containing that word. Therefore, the same word can have different word vectors under different contexts.
code snippet:
import tensorflow_hub as hub
import tensorflow as tf
elmo = hub.load("https://tfhub.dev/google/elmo/2")
# Extract ELMo features
embeddings = elmo.signatures["default"](tf.constant(corpus)
)["elmo"]
print('\nShape of vector: ',embeddings.shape)
print('\nBelow is the vector representation of the sentences:')
print(embeddings)Output:


The output is a 3 dimensional tensor of shape (4, 9, 1024).
The first dimension of this tensor represents the number of training samples. This is 4 in our case
The second dimension represents the maximum length of the longest string in the input list of strings. Which is 9 in our case.
The third dimension is equal to the length of the ElMo vector
Hence, every word in the input sentence has an ElMo vector of size 1024.
These were few text vectorization techniques. I hope you understand the concept better now.
If you need implementation for any of the topics mentioned above or assignment help on any of its variants, feel free contact us

Comentários